
Stable Diffusionを起動します!
Stable Diffusionのインストールや基本的な使い方は予め練習しといてください!
img2img
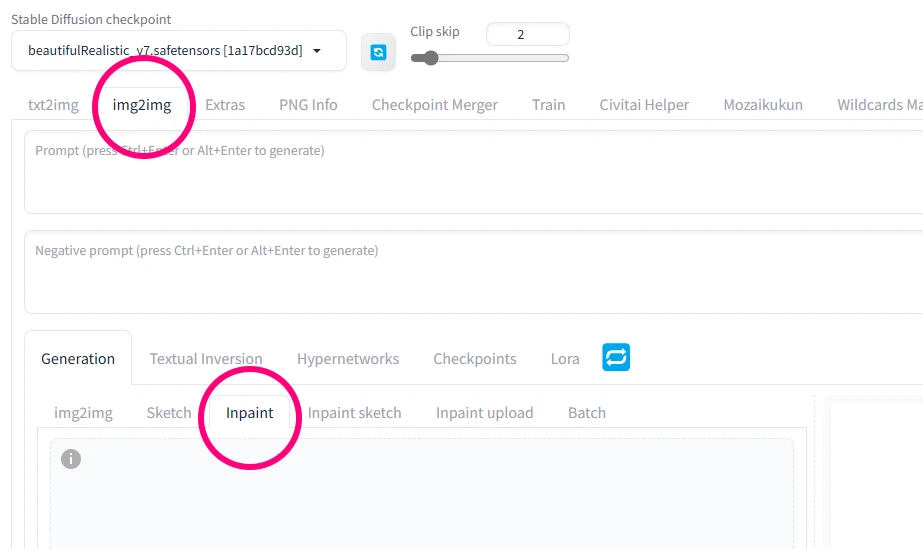
レタッチなので元画像からAI生成をしていきます! img2imgタブに切り替えてください
img2imgに切り替えたら、さらにinpaintタブに切り替えます!
マスク処理ができます
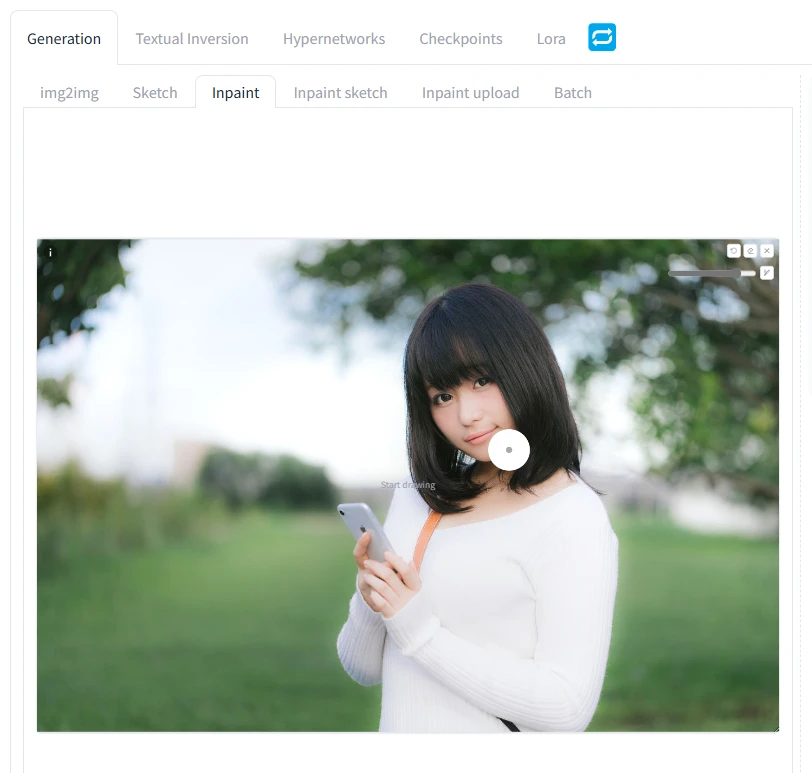
「ここに画像をドロップ- または -クリックしてアップロード」の所にレタッチしたい画像を投げ込みます。今回は某有名なフリー素材の女性の画像を拝借しました
右上に小さくブラシツールがあるのでブラシサイズを変えつつ、マスク(AI生成で変更したい部分)を塗っていきます
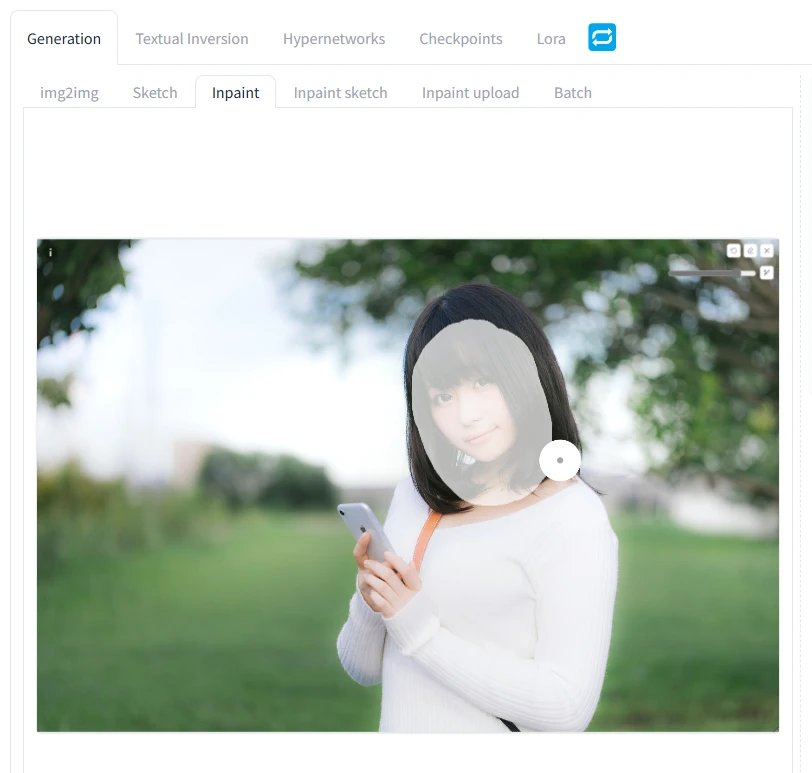
↑の白く塗られた部分がマスク部分です! この塗られた部分だけ、AI生成します
パラメーターを調整
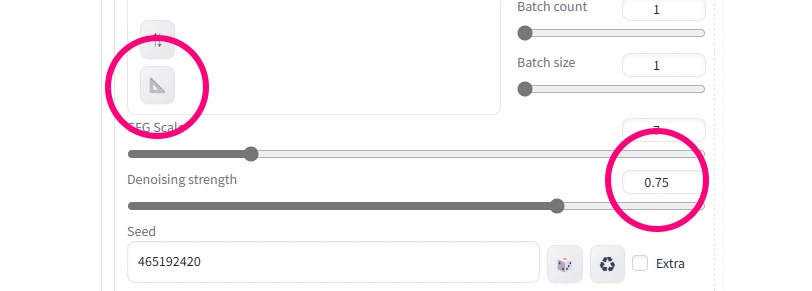
△のマークを押すと元画像のオリジナルサイズが入ります。今回は横1600pxでしたので、AI生成では少し大きめです。AI生成し易い半分くらいの512~768pxのサイズに手動で変えます
デノイズの強さを調整する「Denoising strength」は後程詳しく解説します。ついでにSeed値も固定しておくといいかもしれません
プロンプト入力でAI生成!
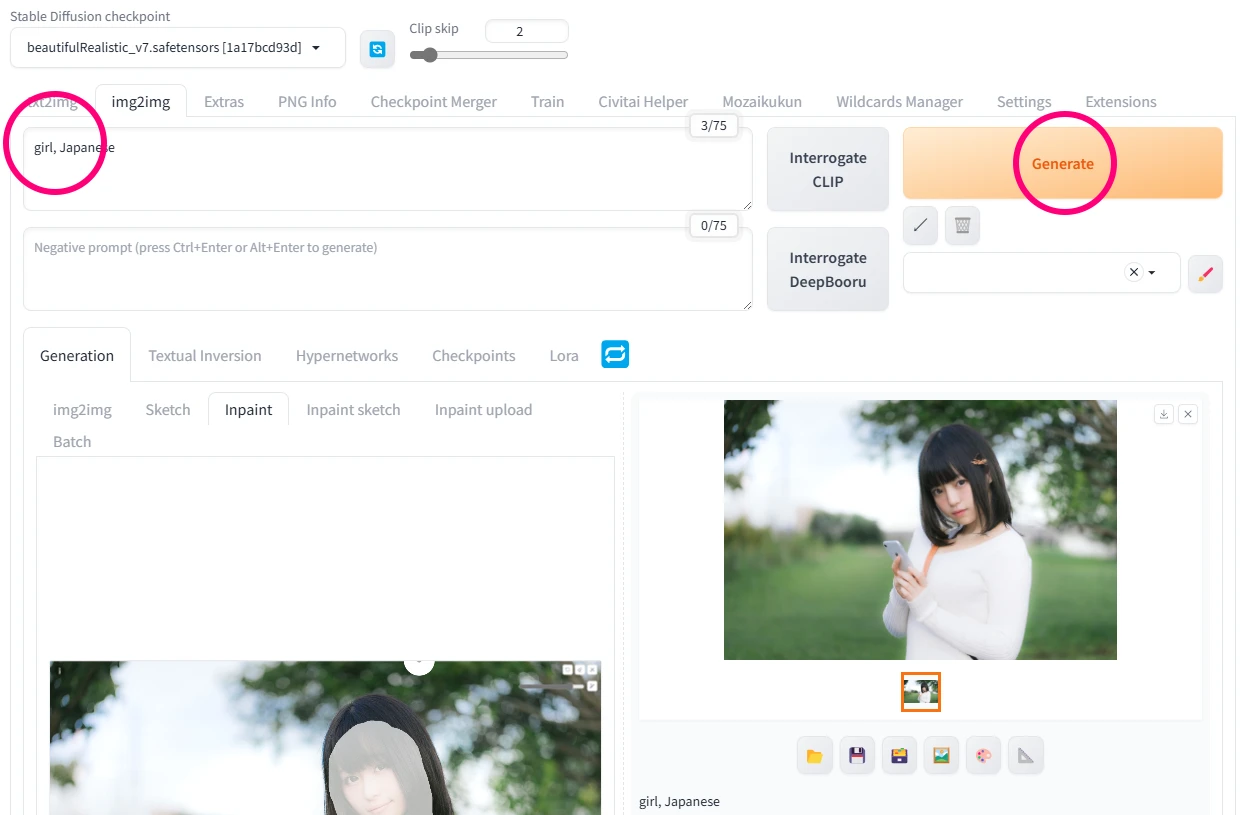
お馴染みのプロンプト入力欄に「girl, Japanese」くらいは入れといた方がいい感じです! ここまで終えたらいよいよGenerateボタンを押して生成します!
(・・・たぶん、まだ変な画像しか生成できないと思いますw)
ADetailerを使用しよう!
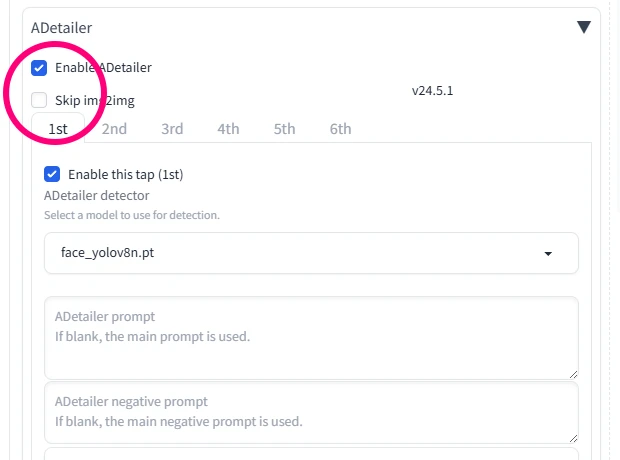
Stable Diffusion経験者にはもう必須のADetailerをONにします。ここでは拡張機能ADetailerの導入方法や使い方は割愛します!
レタッチ完了

これでマスクした部分だけAI生成できました! 他の部分を変えずに顔だけが変わってるのがわかると思います!

生成したままのpngを置いときます(テキストエディタでパラメータ読めますし、Stable DiffusionのPNG infoに投げ込めば数値見れます)
Denoising strengthで微調整
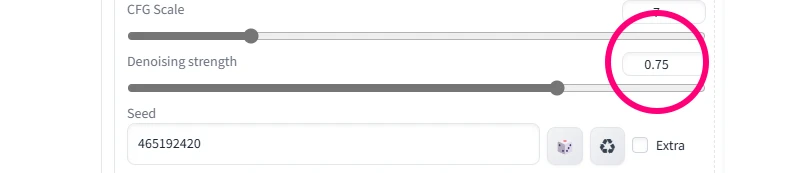
先ほどちょろっと出たDenoising strengthですが、ここで元画像にどれだけ似せるかが調整できます。

0.6~0.7で急激に変わるのがわかります! 0.7以上はもう勝手にAIが描いてるので使えなさそう! このあたりは上手く微調整する感じでしょうか
超細かいことを言うと、ADetailerのInpaint denoising strengthの値も重要だったりしますが、ここでは割愛(0.3~0.4くらいがベター)
checkpoint(モデル)での変化一覧

有名どこのモデルで、強さは0.4と0.7で一覧を作りました。0.4くらいだとわずかな差ですが、0.7だとけっこう変わります
スケールアップ
最初に1600pxの半分にしてしまったので、出力画像は800pxです。このままだと素材としては解像度が足りなくなってくる場合があります! …じゃ、MultiDiffusionとかExtrasでアップスケールすれば? と思いがちですが、そうすると今度は全画像が新たに生成されてしまうんですよね…
なので、高解像度でレタッチしたい場合は重くても「最初の半分にする」をやめて1600px(今回のケース)で生成するのがベターです
ちなみに半分での出力と、そのままで出力では生成結果が異なります。Stable Diffusionに詳しい人なら、解像度をちょっといじっただけで大きく出力が変わるのは経験済みですね…
生成時間は800pxで5秒、1600pxで23秒でした。VRAMが足りなかった場合はForge版とかも検討してみてください
ControlNetのIP-Adapterでいいんじゃね?
さらに上級者の方なら、ControlNetでIP-Adapter使えば似たような顔ができるのをご存知のはず…ですが、やっぱりこれも全体が書き換えられてしまうので、背景が変わったり、デッサンの破綻が出てきます
テスト環境
OS : Windows 11
GPU:NVIDIA GeForce RTX 4060 Ti 16GB
webui:AUTOMATIC1111
今回の800✕533pxだと、ADetailer込みでだいたい5秒という生成スピードでした! VRAMが16GBあるので結構力押しできましたが、もし何度生成しても上手くいかない場合は、解像度を512✕512以下にしてみると上手くいくかもです!
今はStable DiffusionのForge版があるので8GBでも簡単に行けると思いますが、生成スピードを考えるとRTX4060Tiくらいは欲しいですね!
Stable Diffusionとは?
せっかくブログで紹介してるので、少しAI生成のお話を!
現在主流はchatGPTのDALL-E3かもしれません。そもそも言葉から生成するアルゴリズムと、ノイズを除去して生成するStable Diffusionでは絵がまったく異なり、言葉を理解するDALL-E3のほうがとっつきやすいです。じゃ、なんでStable Diffusionを使うかと言うと…それはローカルで動作可能で、レギュレーションに左右されないから。PhotoshopでAI生成を試した方なら経験したと思いますが、ちょっと水着写真の子の一部をAI生成しようとしただけでPhotoshopさんはお怒りになられます! DALLさんも結構曲者ですw その点、Stable DiffusionはNGがありません! とは言え、著作権とかでグレーの部分があったり、モデルや追加学習ファイル(LoRA)によっては肖像権とかも絡んでくるので注意が必要です

